
A Vision Transformer (ViT) is a type of deep learning model that uses the Transformer design, originally made for natural language processing tasks for computer vision tasks. It was first mentioned in a 2020 study paper by Dosovitskiy et al. called "An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale."

CNNs have been the most common architecture for image classification and other computer vision jobs for a long time. ViT, on the other hand, takes a different method by using the Transformer model to process images. This model has been very successful in natural language processing tasks.
ViT's main idea is to break up a picture into small patches and flatten them into a series of 1D vectors. The Transformer architecture then treats these changes as input tokens and works on them. The Transformer model comprises many layers of self-attention and feed-forward neural networks. This lets the model record complex relationships and dependencies between the image patches.
To make ViT work with Transformers' sequential nature, an extra learnable positional embedding is added to represent the image patches' locations. Together with the patch embeddings, these location embeddings are sent to the Transformer layers.
Most ViT models are trained on large datasets like ImageNet using contrastive learning, a type of self-supervised learning. After pretraining, the models can be fine-tuned for specific computer vision tasks, such as finding objects, separating them, or putting them into groups.
ViT has shown some good results and has done as well as CNN-based models on several standard datasets. It also has benefits, like getting information about the global environment and possibly better generalization across different tasks. But because ViT models have a lot of parameters, they take a lot of computing power and can be more expensive to run than traditional CNN models.
Several things have made the Vision Transformer (ViT) model more important in the field of computer vision:
1. Considering global context: ViT models consider global connections and contextual links between image patches. This is especially helpful when it's important to understand the big picture of an image, like when you're trying to figure out what's going on in a scene or when you're making an image.
2. Scaling: The scaling of ViT models has been very good. ViT models can handle images of any size by breaking them into smaller patches. This is different from convolutional neural networks (CNNs), which usually only work with inputs of set sizes. Because of this, ViT models can handle high-resolution images without much extra work.
3. Transfer learning: ViT models already trained on big datasets like ImageNet can be fine-tuned for specific tasks with less labeled data. This ability to transfer learning speeds up model building and improves performance, especially when there isn't a lot of labeled data.
4. Generalization across tasks: ViT models have shown the possibility for better generalization across different computer vision tasks. ViT models, unlike CNNs, can be trained on a big dataset and then fine-tuned on different tasks further down the line. This information that can be shared makes it easier to share knowledge and can help people do better on various vision tasks.
5. Attention mechanism: The self-attention mechanism is a key part of the Transformer design that lets ViT models model complex relationships and dependencies between image patches. This attention method lets the model focus on important patches and notice long-range dependencies, which helps it understand the meaning of images.
6. Comparing ViT models to CNNs, interpretability is better with ViT models. Since each image patch is viewed as an input token, the attention maps can be used to see which image patches impact the final predictions most. This can help find important parts of a picture and determine how a model acts.
Even though ViT models have shown some good results, they are still an area of study. The goal of ongoing work is to improve their performance, efficiency, and ability to be used for a wide range of computer vision jobs.
Several key parts comprise a Vision Transformer (ViT) model's design. Here's a summary of the ViT architecture at a high level:
1. Patch Extraction: The picture is divided into smaller squares of the same size. Each patch shows a different part of the picture. Then, these patches are smoothed into a series of one-dimensional vectors.
2. Patch Embeddings: Each patch goes through an embedding layer, which maps it to a place with more dimensions. This embedding layer usually comprises a linear projection followed by a non-linear activation function (like ReLU).
3. Positional Embeddings: Learnable positional embeddings are added to the patch embeddings to take into account where the patches are. These positional embeddings store each patch's relative or exact location in the picture.
4. Transformer Encoder: The patch embeddings and the positional embeddings go into a stack of Transformer encoder layers. Each encoder layer has multi-head self-attention processes and feed-forward neural networks.
a) Self-Attention: The mechanism for self-attention lets each patch pay attention to all the other patches in the series. It shows how patches rely on each other by giving different attention weights to each patch, which shows how important each patch is for the final prediction.
b) Feed-Forward Networks: Each patch gets its own feed-forward neural network after the self-attention step. After that, it has a fully connected layer and a non-linear activation function (like ReLU). This step adds non-linear transformations to capture the complex relationships between patches.
5. Classification Head: At the end of the Transformer encoder stack is a classification head that makes the final predictions. Most of the time, the output of the last Transformer layer is put together by taking the mean or max pooling process over the sequence of patch embeddings. This combined representation is sent through a fully connected layer with a softmax activation function to make class probabilities for picture classification.
During training, the ViT model is usually pre-trained on a large dataset using self-supervised learning methods, such as contrastive learning, to learn how to represent things meaningfully. After pretraining, the model can be fine-tuned using labeled data for specific computer vision jobs.

There are several steps to building and training a Vision Transformer (ViT) model. Here's a summary of what will happen:
1. Preparing the data: First, you must prepare your training data. This means getting the pictures and putting them through some processing first. In the preprocessing steps, the pictures may be resized to be the same size, the pixel values may be normalized, and the dataset may be split into training, validation, and test sets.
2. Model design: Define the design of the ViT model, including the number of Transformer layers, the size of the patch embeddings, the number of attention heads, and any other hyperparameters. Deep learning tools like PyTorch or TensorFlow can be used to build the architecture.
3. Pretraining: It is important for ViT models to do pretraining. Usually, you start the model with random weights and train it on a large-scale dataset using self-supervised learning methods. Contrastive learning is a popular way for a model to learn independently. In this method, the model learns to tell the difference between positive and negative pairs of augmented pictures. The goal is to encourage similar representations for augmented views of the same picture and different representations for different images.
5. Fine-tuning: The ViT model can be fine-tuned on specific computer vision tasks using labeled data after pretraining. This includes setting up the pre-trained weights and updating them using a smaller labeled dataset specific to your task. For example, you would use a labeled dataset with sets of images and labels to classify images.
During training, you send groups of images through the ViT model and figure out the difference between the outputs you expected and the real labels. Backpropagation and gradient descent optimization methods, such as Adam or SGD, are often used to minimize the loss. The training process can be improved by tuning the learning rate, batch size, and other hyperparameters.
Once the training is done, try the trained ViT model on a separate validation or test dataset to see how well it works. Depending on the job, determine the right evaluation metrics, such as accuracy, precision, recall, or F1 score.
6. Iterative Refinement: Depending on how well the model works, you may need to repeat the training process and make changes. This can be done by adjusting the hyperparameters, changing the model's architecture, adding more training data, or using regularisation methods to make the model more general.
Remembering that the implementation details can change based on the framework and libraries used is important. Open-source tools like PyTorch and TensorFlow have ready-made modules for building and training ViT models, which can make implementing them easier. Also, training a ViT model usually needs a lot of computational resources, like GPUs or TPUs, because it has a lot of factors and is hard to compute.
Here's a step-by-step guide on implementing a Vision Transformer (ViT) model for image classification using the PyTorch framework:
Step 1: Import Libraries
First, import the necessary libraries for your implementation:
import torch
import torch.nn as nn
import torchvision.transforms as transforms
from torchvision.datasets import CIFAR10
from torch.utils.data import DataLoader
Step 2: Prepare the Dataset
Load the CIFAR-10 dataset or any other dataset you want to use for image classification. Apply appropriate data transformations, such as resizing and normalization.
# Define data transformations
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
])
# Load CIFAR-10 dataset
train_dataset = CIFAR10(root='./data', train=True, download=True, transform=transform)
test_dataset = CIFAR10(root='./data', train=False, download=True, transform=transform)
# Create data loaders
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
Step 3: Define the Vision Transformer Model
Implement the architecture of the Vision Transformer model using PyTorch's nn.Module class.
class VisionTransformer(nn.Module):
def __init__(self, num_classes):
super(VisionTransformer, self).__init__()
# Define the architecture of the Vision Transformer
# ...
# Implement the patch embeddings, positional embeddings, and Transformer encoder layers
# Classification head
self.cls_token = nn.Parameter(torch.zeros(1, 1, 768))
self.fc = nn.Linear(768, num_classes)
def forward(self, x):
# Implement the forward pass of the Vision Transformer
# ...
# Combine patch embeddings, positional embeddings, and pass through the Transformer encoder layers
# Apply global average pooling and pass through the classification head
return logits
Step 4: Instantiate the Model
Create an instance of the Vision Transformer model with the desired number of classes.
model = VisionTransformer(num_classes=10)
Step 5: Define Loss Function and Optimizer
Specify the loss function and optimizer for training the model.
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
Step 6: Training Loop
Implement the training loop to train the Vision Transformer model on the CIFAR-10 dataset or your chosen dataset.
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
num_epochs = 10
for epoch in range(num_epochs):
for images, labels in train_loader:
images = images.to(device)
labels = labels.to(device)
# Forward pass
logits = model(images)
loss = criterion(logits, labels)
# Backward pass and optimization
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}")
Step 7: Evaluation
Evaluate the trained model on the test dataset to measure its performance.
model.eval()
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
logits = model(images)
_, predicted = torch.max(logits.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / total
print(f"Test Accuracy: {accuracy:.2f}%")
This is a basic outline of how you can implement and train a Vision Transformer model for image classification using PyTorch. Remember to adjust the architecture and hyperparameters based on your specific requirements and dataset.
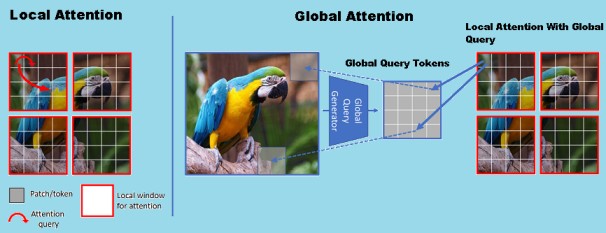
The Vision Transformer (ViT) model has become a robust architecture for computer vision tasks by applying the Transformer's success in natural language processing to image processing. It divides an image into patches, then processed by several Transformer encoder layers.
ViT models have several benefits, such as being able to understand world context, being able to handle high-resolution images, being able to learn from other tasks, and being able to be used for a wide range of tasks.
Also Read:


.jpg)